GPU: 从物理到 VM 到 container 内
TL;DR
让部署在 VM 之上的 container 内部的 app 使用 nvidia GPU
- 先将 host 的 GPU passthrough 到 VM
- 使用 nvidia 的 container runtime 将 GPU 暴露到 container 内部
- 在 k8s 中借助 device-plugin 来 schedule
在 Proxmox VE 中进行 Passthrough
配置 host
添加 iommu 到 grub
编辑文件:
$ vi /etc/default/grub
可以看到有一行是:
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
在这里视 CPU 情况加上 intel 或是 amd 的 iommu 参数:
GRUB_CMDLINE_LINUX_DEFAULT="quiet amd_iommu=on"
# or
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on"
修改完成后更新 grub:
$ update-grub
添加 vfio modules
编辑 modules 文件:
$ vi /etc/modules
添加:
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
remap IOMMU interrupts
添加参数来允许 iommu unsafe interrups:
$ echo "options vfio_iommu_type1 allow_unsafe_interrupts=1" > /etc/modprobe.d/iommu_unsafe_interrupts.conf
$ echo "options kvm ignore_msrs=1" > /etc/modprobe.d/kvm.conf
添加 blacklist
让 host 不使用我们的目标设备, 从而留给 vm:
echo "blacklist radeon" >> /etc/modprobe.d/blacklist.conf
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
echo "blacklist nvidia" >> /etc/modprobe.d/blacklist.conf
将 GPU 添加到 vfio
使用 lspci 查看设备, 找到目标的 GPU (比如我这是一块 GT1030):
$ lspci
...
26:00.0 VGA compatible controller: NVIDIA Corporation GP108 [GeForce GT 1030] (rev a1)
26:00.1 Audio device: NVIDIA Corporation GP108 High Definition Audio Controller (rev a1)
...
找到之后查看设备的 vendor ID:
$ lspci -n -s 26:00
26:00.0 0300: 10de:1d01 (rev a1)
26:00.1 0403: 10de:0fb8 (rev a1)
然后将 vendor ID 写入 vfio 配置中:
$ echo "options vfio-pci ids=10de:1d01,10de:0fb8 disable_vga=1"> /etc/modprobe.d/vfio.conf
然后更新 initramfs 并重启:
$ update-initramfs -u
$ reset
配置 VM
新建 VM
先按照一般的方法创建 VM, 完成之后不启动 VM.
修改以下的配置:
- SCSI Controller: VirtIO SCSI Single
- Machine: q35
- BIOS: OMVF (UEFI)
同时因为 BIOS 改成了 UEFI 方式, 所以需要新建一个 EFI 磁盘.
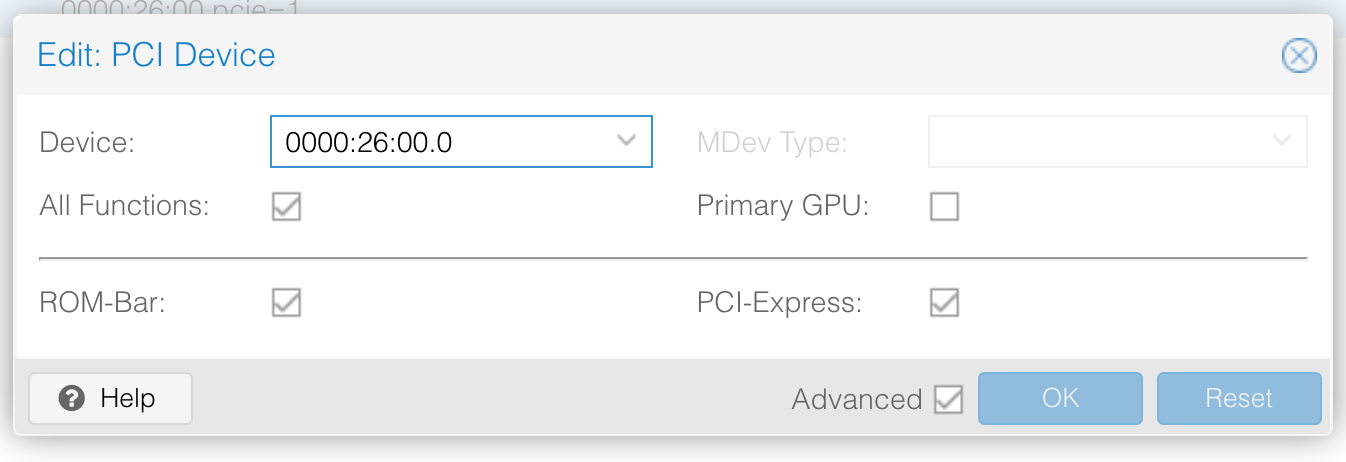
添加 GPU
添加 PCI Device, 找到 GPU 并添加:
关闭 VM 的 secure boot
对于大多数的 Linux Distro, 需要关闭 secure boot 来获得访问 EFI 磁盘的权限, 不然可能会在开机的时候报:
bdsdxe failed to load boot0001 EFI access denied
只要在 VM 启动的时候按 ESC 然后到 Device Manager 里面把 Attempt Secure Boot 的 X 去掉就可以.
驱动安装和测试
安装完 VM 的系统之后可以先在 VM 中测试 GPU 能不能被看到, 正常的话输出的信息应该和 host 上基本一样 (除了序号):
$ lspci
...
01:00.0 VGA compatible controller: NVIDIA Corporation GP108 [GeForce GT 1030] (rev a1)
01:00.1 Audio device: NVIDIA Corporation GP108 High Definition Audio Controller (rev a1)
...
然后可以去 nvidia 的官网 下载 Linux 的驱动 (找到对应型号和平台):
$ wget "https://us.download.nvidia.com/XFree86/Linux-x86_64/510.54/NVIDIA-Linux-x86_64-510.54.run"
先安装一下编译需要的一些库, 我这里的系统是 ubuntu server:
$ sudo apt install build-essential
然后需要先禁用掉 Linux 自己的开源驱动 Nouveau kernel driver:
$ sudo vi /etc/modprobe.d/blacklist-nouveau.conf
添加:
blacklist nouveau
options nouveau modeset=0
然后重新生成 initramfs 并重启:
$ sudo update-initramfs -u
$ reboot
之后就可以进行官方驱动的安装:
$ chmod +x NVIDIA-Linux-x86_64-510.54.run
$ sudo ./NVIDIA-Linux-x86_64-510.54.run
完成后可以使用 nvidia-smi 查看显卡状态:
$ nvidia-smi
Wed Feb 16 03:10:00 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 38% 33C P0 N/A / 30W | 0MiB / 2048MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
将 GPU 暴露到 container 内部
配置 container runtime
安装 nvidia-docker 和 runtime:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt update && sudo apt-get install -y nvidia-container-toolkit
$ sudo apt install nvidia-container-runtime
$ sudo apt-get update && sudo apt-get install -y nvidia-docker2
更新 daemon.json, 将默认的 runtime 修改为刚刚安装的 nvidia-container-runtime:
$ sudo vi /etc/docker/daemon.json
使用如下的配置:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
重启一下 docker daemon:
$ sudo systemctl restart docker
容器内测试
使用 nvidia/cuda 这个 image 来跑 nvidia-smi 看看容器内部能不能访问到 GPU, 正常的话输出信息应该和 VM 内基本一致:
$ docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
Wed Feb 16 03:32:28 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 38% 34C P0 N/A / 30W | 0MiB / 2048MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
同时可以用 tensorflow 跑一个模型来进行一定的 stress test
$ docker run --rm -ti --gpus all tensorflow/tensorflow:latest-gpu
在 k8s 中使用: 以 jellyfin 为例
在 k8s 中, 如果需要让 pod 访问特殊的硬件资源, 需要 device plugin 的帮助, 因此需要先部署 nvidia 提供的 device plugin:
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/master/nvidia-device-plugin.yml
检查一下资源是不是已经部署, 值得注意的是, 虽然我只有一个 node 上面有 GPU, 但是 daemonset 在部署的时候并没有机制去检查, 因此会在所有的 node 上面部署. 也可以自己去修改一下 device-plugin 的 node-selector 参数来让它仅部署到对应的 node (没有测试会不会有问题):
$ kubectl get daemonset -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system nvidia-device-plugin-daemonset 4 4 4 4 4 <none> 1m
...
接下来部署 jellyfin, 测试使用 GPU 来 transcode.
首先当然需要给对应的 node 打一个 label, 从而将 pod 调度到目标 node 上:
$ kubectl label node mufti-4 nvidia.com/gpu=dedicated
向 jellyfin 的 deployment 添加 nodeAffinity 配置:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu
operator: In
values:
- dedicated
另外, 为了使用 GPU, 很多 image 都可能需要 pass 一些额外的环境变量, 比如 jellyfin 这里需要:
env:
- name: NVIDIA_DRIVER_CAPABILITIES
value: "all"
- name: NVIDIA_VISIBLE_DEVICES
value: "all"
部署之后就可以在 jellyfin 的选项里面打开 Hardware acceleration, 选择 Nvidia NVENC. 由于我这张卡 GT1030 实在太弱了, 对于主流的 H264 和 H265 4:2:0 只支持 decode 不支持 encode, 因此还要特意把下面的 encoding 相关选项关掉. GPU 对 transcoding 的支持情况可以在 nvidia 的 developer 文档里面找到.
![]()
播放时使用 nvidia-smi 查看 load, 可以看到 GPU 被成功调用:
$ nvidia-smi
Wed Feb 16 08:31:29 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | N/A |
| 35% 39C P0 N/A / 30W | 951MiB / 2048MiB | 36% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1719 C ...ib/jellyfin-ffmpeg/ffmpeg 949MiB |
+-----------------------------------------------------------------------------+