A Brief History of Intelligence 主线梳理
简单总结 TL;DR
因为类比通常只是帮助人理解抽象概念,而不是用来阐释内在逻辑的。因此我一直认为,将深度学习的机制类比成生物神经元的工作,是一种很不严谨的比喻,更多是受到了 naming 的影响。但是读了本书才意识到,二者的内在逻辑其实比我原先想象的更加接近,深度学习的发展历史受神经科学的影响也比我想象中更深。
Intelligence 是可解释的,而且是可以被分层解释的,甚至是可以以进化的时间线为轴来解释的。这里的每一层都是人类的进化史上的一次重大突破。
- 拥有双侧对称这样的特征的动物拥有了更强的移动能力,但是对操控提出了更高的要求,为此他们进化出了用神经元来控制如何移动、转向的能力。这些信号根据其积极消极、活跃消沉的程度可以简单组合成动物四个象限的状态,形成原始的情感,动物也拥有了多巴胺、血清素这样的神经调节剂。随后,这些动物又学习到了利用神经信号出现的规律去预测实际的事件,拥有了反射的能力。
- 脊椎动物改进了多巴胺的作用机制,做到了在强化学习中将奖励和强化解耦,形成了 TD 学习的能力。同时,多个神经元可以联合工作来进行复杂的模式识别。同时,海马体的出现为真正世界模型的形成打下了基础。
- 哺乳动物进化出了可以模拟一切的结构——新皮层,利用识别模型-生成模型的架构做出了一个可以预测一切的世界模型,赋予了哺乳动物替代性试错、反事实学习等能力。然后 aPFC 出现,对新皮层本身再进行预测,从而可以控制新皮层进行策略搜索,做到了基于模型的强化学习。
- 灵长类动物的政治生活催发了对他人心智进行建模的需求,gPFC 应运而生,可以预测 aPFC 的运作,做到了一种逆向的强化学习,从而形成一种对自我的认知和对他人的认知,可以从观察他人之中去学习。
- 人类开始有了语言,经验以及新皮层的模拟都可以被分享,知识于是可以被积累,最后达到一个奇点,形成了今天的我们。
| 生物 | 出现的结构 | 能力 | 学习方式 |
|---|---|---|---|
| LUCA | |||
| 动物 | 神经元 | 内部消化、无条件反射 | |
| 双侧对称动物 | 大脑 | 原始情感、条件反射 | 从实际行动中学习 |
| 脊椎动物 | 皮层、海马体 | TD 学习、模式识别 | 从实际行动中学习 |
| 哺乳动物 | 新皮层、aPFC | 世界模型、基于模型的强化学习 | 从想象中学习 |
| 灵长类动物 | gPFC | 心智能力(对他人建模) | 从观察他人的实际行动中学习 |
| 人类 | 语言 | 从他人的想象中学习 |
原始智能
在这一切的突破之前,需要神经元出现来打下基础。
首先根据现在的研究,生物起源于碱性热液喷口,最初的生物都是仰赖离子浓度的梯度提供的能量来生存的,在这个时期,不同的生物没有明显的竞争。但是当叶绿体和线粒体产生,光合作用和呼吸作用出现之后,这种和平就被打破了,因为不从事光合作用的生物的能量来源是那些从事者的鲜美内脏。
今天生物分类中次顶层的一级是「界」(kingdom),其中有植物界、动物界和真菌界,按照光合作用与否的角度来说,植物是进行光合作用的,而动物和真菌是享用植物的成果的。但在这其中真菌和动物的分野就在于采用了非常不同的猎食方法:
- 真菌在外部消化猎物
- 真菌一般会在死亡植物的边上散开孢子,然后发展出毛状丝,分泌酶,并吸收释放出的养分
- 而动物在内部消化猎物。
- 而动物普遍会有一个腔体去束缚住猎物,然后在内部慢慢进行消化
- 动物的这种特点就需要这个腔体能够在捕捉猎物的时候快速关闭,这就是最早期神经元的作用:感受里面有猎物,然后传到信号到肌肉,将腔体关闭
神经元的两点关键工作机制:
- 对其中传递的信号必须有一套编码的机制
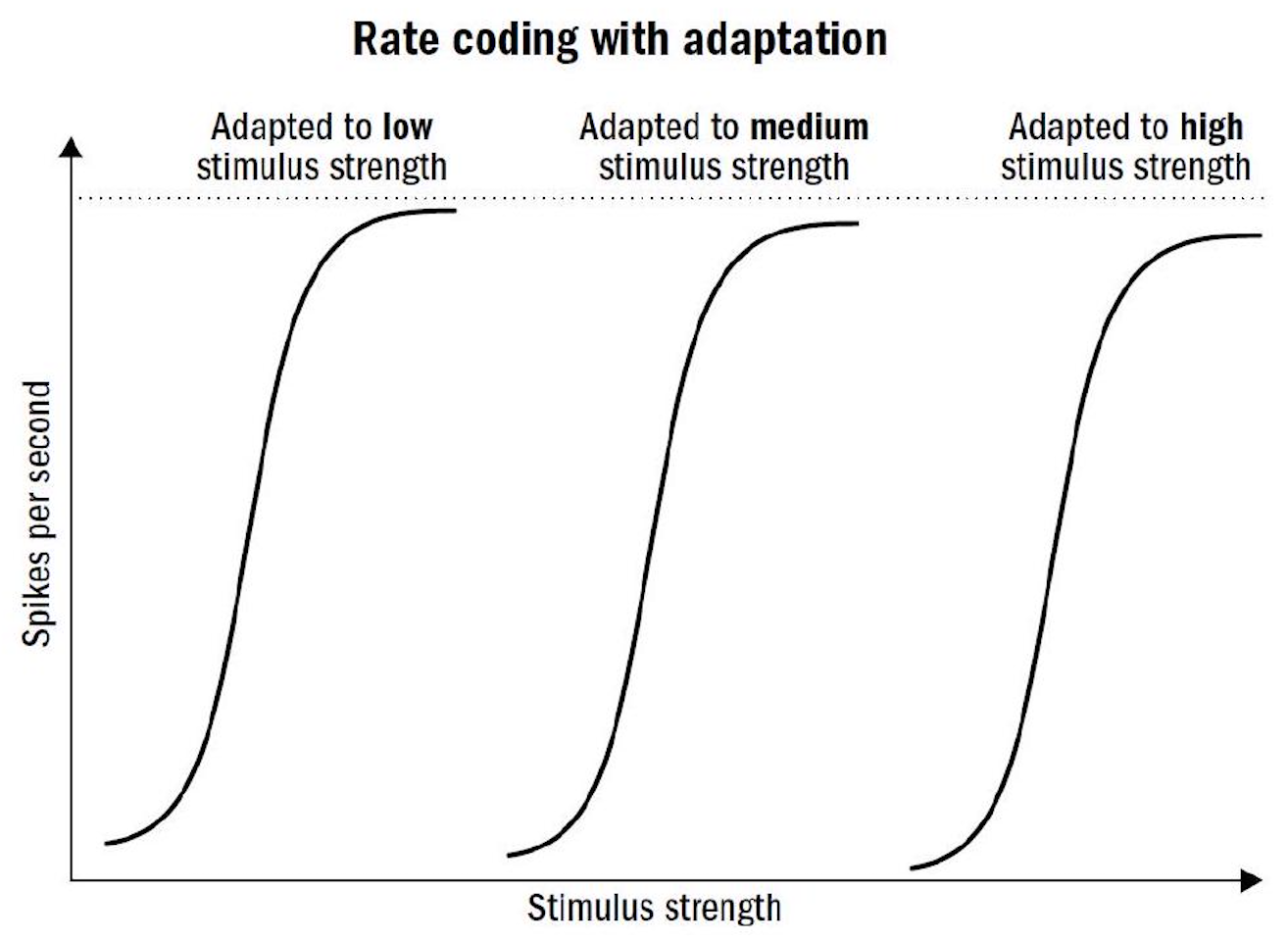
- 神经信号的强度实际上都是一样的,只是在感受的对象强度比较高的时候会释放更加高频的神经脉冲
- 比如视神经信号的强度在暗的地方和亮的地方是完全一样的,只是在亮的地方神经脉冲会释放更加频繁
- 神经元在这里有一定的适应能力
- 脉冲频率和感受对象的强度的关系不是线性的,而是会有一个非线性的变换,类似深度学习中的激活函数,适应一个环境的过程中可以调整这个激活函数比较敏感的区域
- 比如人能感受到环境亮度(照度)可能是差上万倍的,也就是 Dynamic Range 很大,但是脉冲频率并不会差这么多
Breakthrough #1: Steering and the First Bilaterians
操控
我们今天可以看到绝大多数的动物都是「双侧对称」(bilateral symmetry) 的,即左右对称然后有前后性。这种结构在移动能力上是更强的,因为负责移动的结构主要只需要负责前后的移动。但是这对操控 (Steering) 也提出了更高的要求,因为要将身体转向到正确的方位。我们的祖先就是在这样的要求之下进化出了一套简单的导航机制,形成了一个简单的大脑。
现代线虫可以看成是和早期的双侧对称动物类似,它们的大脑只有三百多个神经元,但是能完成通过嗅觉去移动来寻找食物这样的操控过程。整个机制非常简单:线虫的一些神经元会感受食物释放的分子的浓度(也就是气味),然后给前进的肌肉释放正向的信号,敦促向前;还有一些神经元是感知浓度降低的,或者是感受自己已经吃饱了的(也就是说有感受内部的神经元),或者是感受危险的,他们连接到控制转向的肌肉,让它进行转向。
情感
实际可能会稍微更复杂一些。感觉神经元将初始信号传递给少数关键的中间神经元,这些信号可以都可以从两个角度去评价:是积极的还是消极的 (valence),是高唤醒的还是低唤醒的 (arousal),这样两两组合就可以形成一个四象限的坐标系,这就是原始的情感。
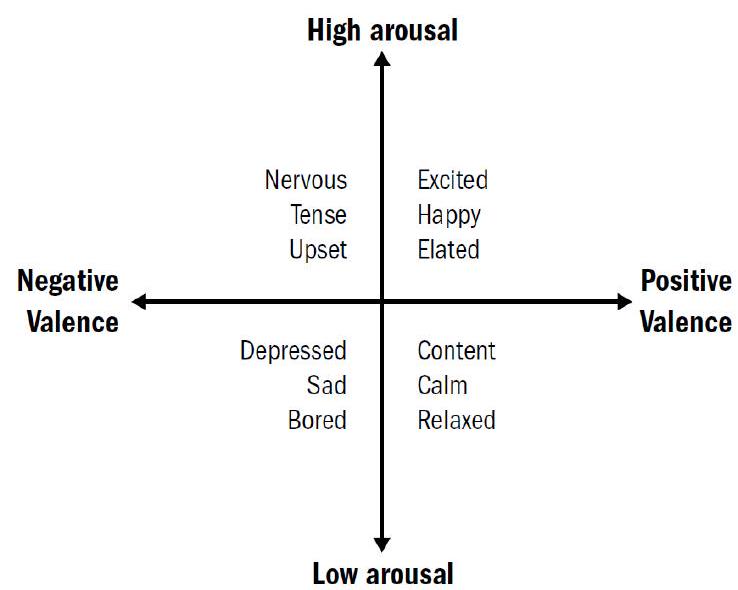
对于线虫来说:
- positive valence, high arousal:缓慢的移动、频繁的转向 (检测到周边有食物)
- positive valence, low arousal:不动 (比如吃饱了)
- negative valence, high arousal:快速移动、不频繁的转向(逃跑)
- negative valence, low arousal:不动(长期压力)
这四个象限完全可以对应到人类:
- positive valence, high arousal:兴奋、激动
- positive valence, low arousal:满足、放松
- negative valence, high arousal:紧张、恐惧
- negative valence, low arousal:抑郁、忧伤
也就是说所谓的「情感」可能就是从这些用来帮助寻找食物和逃跑的状态中诞生的。
我们现在的情感都是持续存在的,比如悲伤的情绪会持续几个小时甚至好几天。这从线虫这里也是非常说得通的:因为比如食物的气味浓度不是一个平缓的梯度,可能会一下子闻到然后后面又消失了,那么这种「情感」(在这里应该是 positive valence, high arousal) 持续存在的话可以驱使线虫继续寻找食物;类似的,逃跑的时候也应该要持续逃跑,这样才更容易生存。
不管是人类还是线虫,都是通过神经调节剂来控制情感,这里最重要的两种就是多巴胺 (Dopamine) 和血清素 (Serotonin)。 对线虫来说,多巴胺的神经元会从头部伸出小附肢,监测食物的存在,当发现有食物的时候就释放多巴胺,也就是进入 high arousal 的状态。而血清素神经元会监测喉咙中的食物,有食物的时候就会释放血清素,触发饱腹感,也就是进入 low arousal 的状态。
也就是说,多巴胺的作用是驱动去寻找食物,告诉你周边有 something good;而血清素的作用是告诉你 something good 正在发生。对人类来说,看到食物、看到性感的异性都会分泌多巴胺,而吃美味食物、性高潮、完成 todo item 的时候都会分泌血清素。
另外,在有紧急情况的时候,动物会释放肾上腺素等化学物质进行应急,触发战斗或逃跑反应,同时抑制短期内非必要的生理功能,比如笑话、免疫、繁殖等。而这种情况显然是不能长期持续的,所以之后需要一种反调节机制来恢复正常,这时候就会分泌阿片类物质。所以阿片类物质有促进食欲,增进免疫系统、消化系统功能恢复,以及抑制负情绪神经元来减少疼痛感的作用。因此阿片经常被使用来作为止痛药。
对线虫做实验可以发现,如果让它长期处于危险环境中,它经过了应急状态 (high arousal) 一段时间后,会主动放弃,变成 low arousal 状态。因为自然选择显示了,应急状态这种非常消耗能量的机制是不能长期保持的,如果一直危险那其实还是保留一定的能量更有可能生存下来。反映到今天人类身上就是,长期处于慢性压力之后激活血清素,神经会关闭唤醒和动机,进入 low arousal,形成一种习得性的无助,也就是抑郁。
预测
巴甫洛夫的条件反射实验实际上揭示了一种原始的联想学习能力:狗能学习到蜂鸣声和食物之间的关联。
这种学习能力在线虫这样神经元极少的动物上也有。把线虫分别放在清水也盐水中,不放食物,然后再把他们转移到一部分放了盐块的环境中,之前在清水中的线虫会去尝试接近盐块,而盐水中的线虫就不会。同时这种能力是只有双侧对称动物才有的,比如海葵就没有,将光和电击一起施加于海葵,但是海葵永远只对电击有反应,而不会对光照有反应。
如果之后施加多次二者不相关的信号,比如蜂鸣了但是不给食物,动物对于二者的关联反应就会减弱。但是同时,如果之后再出现关联,那么这种联想能力会迅速恢复,我们称之为「再习得」。这也很合理:因为自然界中可能两种东西确实是相关的,某几次不相关其实只是偶然的,再习得的机制可以帮助排除偶然的影响。
在学习关联的过程中,有一个问题就是外界的信号是有很多而且不间断的,那么哪个才是和目标的那个相关联的呢?这个问题在强化学习中被称为「信用分配问题」 (The Credit Assignment Problem),而动物实际上也有这个问题,但是有这几种方式来解决:
- 资格追踪 (eligibility traces):比如只有有食物之前的一秒钟之内发生的信号才有效
- 遮蔽 (overshadowing):只选择最强的信号,其他那些比较弱的信号就忽略了
- 潜抑制 (latent inhibition):过去经常发生的刺激会被抑制,也就是说频繁发生的那些事件会被当作一种背景音
- 阻断 (blocking):只追踪单一线索,如果产生了联结就阻止其他线索与目标的联结
这种学习应该都是通过神经元之间连接的突触的强弱改变来达成的。比如如果两个神经元之间的突触比较强,那么输入神经元只要释放很弱的信号就能激活输出神经元,反之则需要非常强的信号才能激活。 而突触有很多机制来增强或者削弱,比如可能是突触中有某种蛋白质机制,可以检测到两端的神经元是否在相似的时间发放,如果是的话就增强突触。这种机制由心理学家 Donald O. Hebb 在 1940 年代提出,因此叫作 Hebbian 学习。而实际情况会稍微更复杂一点,比如突触中有某些分子机制可以达成更加细节的监测,比如检测到输入神经元的发放时间要比输出的早,这样才建立关系,以此来形成资格追踪的效果。
Breakthrough #2: Reinforcing and the First Vertebrates
TD 学习
计算机领域的强化学习始于 1950 年代,普林斯顿的博士生 Marvin Minsky 试图用来让机器来在迷宫中导航,训练过程很简单:如果成功走出迷宫就发放奖励。但是这个算法的运行效果并不好,无法 handle 比较复杂的场景。主要原因就是时间长了之后,机器走过的步数可能有几百步,哪些应该被认为是好的哪些应该被认为是坏的是不明确的,这时候只有对于这几百步的总体奖励是不够的。这个问题实际上也是一种信用分配问题,但是是时间上的。
直到 1984 年,Richard Sutton 的博士论文提出了解决时间信用分配的问题的算法,就是用「预测奖励」来取代「实际奖励」。就是 Sutton 提出了 Actor-Critic 模型,其中 Actor (演员)执行动作,Critic (评论家)来评价当前动作应该给多少奖励。比如在下跳棋的时候,前 9 步 Critic 一直认为是均势,然后第 10 步 Actor 执行了一个妙手改变了局势,Critic 就会得出这一步应该给很高的奖励。这就是 TD 学习 (Temporal-Difference)。 但是 Sutton 的这个逻辑是循环的:Actor 能够知道应该做什么行为取决于 Critic 对其的评价,而 Critic 能够知道在给定棋盘的获胜可能性取决于 Actor 未来的行为。
到了 1989 年,IBM 的 Tesauro 偶然发现了 Sutton 的想法,然后将其付诸实施,用来下双陆棋,做法就是同时训练 Actor 和 Critic,最终得到了 TD-Gammon,是当时下双陆棋的 SOTA。这个证明了对机器做强化学习是可行的,于是后世被用来做各种事情,很多都达到了人类的水平。
强化学习被证明在机器上是有效的,但是不确定这只是一种巧妙的算法,还是确实是生物得到智能的一种通用的模式。从对多巴胺的功能的更加深入的研究来看,应该是后者。
一个实验是:给猴子以几何图片,然后一段时间后给糖水,然后测量多巴胺神经元的活动水平。会发现一开始的时候猴子在获得糖水的时候多巴胺神经元活动水平很高,但是几次之后就变成了看几何图片的时候神经元活动水平很高,真正喝到糖水的时候没什么反应了。这说明了多巴胺实际上是一种对于预期的奖励,如果有对未来好事的预期,就会分泌多巴胺。而对猴子来说,到后面看到几何图片的时候就是得到这种预期的时候,因此多巴胺是在这里分泌的,真正得到享受其实并没有改变预期。
另外更加有意思的是一些细节也和我们在机器上实现强化学习的手段相同,让猴子意识到 4 秒之后会有糖水和 16 秒之后会有糖水,这两种情况下看到几何图片的那个时刻的多巴胺神经元活动水平是不同的,4 秒之后的这个会更强。这个就是一种 discounted reward,更近的好事会有更强的奖励,而遥远的好事就要打折扣。
所以也就是说,多巴胺不是奖励的信号,是强化的信号,是希望动物对达到当前的情况所做出的行为进行强化,能够多做这样的行为。所以正如 Sutton 最早发现的那样,强化和奖励是解耦的,这样的训练才是有效的。这也是为什么人类会对多巴胺奖励上瘾,即便实际上没有什么真正的享受。
之前的线虫的多巴胺是对应的「附近有好东西(食物)」,其实和这里更复杂的多巴胺的机制是类似的,它就是在强化要继续这样寻找的过程,所以很能想象为什么多巴胺演化成了这里复杂的机制。
模式识别
有一个问题是,很多的信号都不是通过单一受体来感知的。比如闻到某种气味,实际上是多种气体分子联合被嗅觉神经感受到的结果。也就是说在进行识别的时候是一组神经元共同工作去监测一个模式,这就是「模式识别」。
线虫这样的动物的感知能力仅局限于用单个神经元,而模式识别的能力是脊椎动物独有的。
模式识别是非常困难的,比如对于动物来说,美味的猎物的气味和危险的捕食者的气味可能在很多方面(很多气体分子)上都是相似的。以鱼的嗅觉为例,嗅觉神经元会将其输出发送到大脑顶部的一个结构,称为「皮层」(Cortex)。这边的神经元是「锥体神经元」,拥有数百个树突 (Dendrites,用以输入) 和上千个突触 (Synapse,用以输出)。
从嗅觉输入到皮层的连接很有意思,我们称之为扩展和稀疏:
- 一是它会进行一个升维(扩展):更少的嗅觉神经元连接到了更多的皮层神经元
- 二是它不是全连接的(稀疏):一个特定的嗅觉神经元只会连接到一部分的皮层神经元
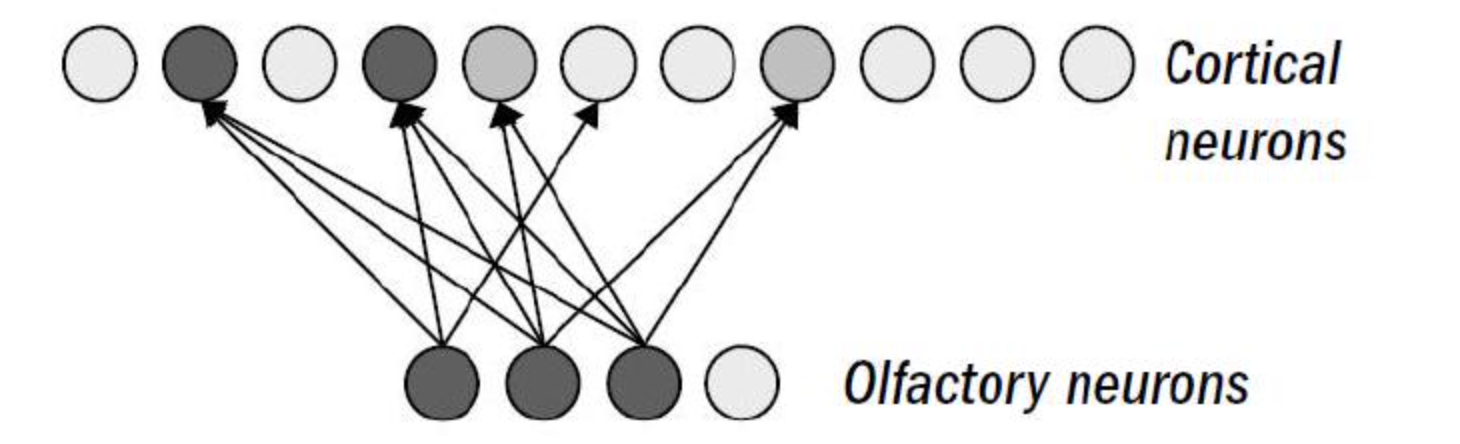
这种连接方式可能就是帮助解决辨别问题的方法,比如尽管捕食者的气味和食物的气味的模式有重叠的地方,但是激活的皮层的神经元将是不同的,这个被称为「正交化」(Orthogonalization) 。
同时还要有能力解决泛化的问题:比如两次的气味可能是类似但是不完全一致的。所以当一个气味模式激活了一组皮层的神经元的时候,这一组神经元会通 Hebbian plasticity 连接在一起,也就是形成一种自我关联。这样,之后这个模式中只有一部分的神经元被激活,也会激活整个模式。也就是说动物形成了这样的一种记忆的寻址方式:通过一个记忆的子集来寻址。
好奇
强化学习实际上是两个对立过程的统一:
- 强化行为:希望下次仍然做同样的事情
- 新行为:对没做过的行为进行探索,这样才有可能能找到好的行为
在机器学习中,这种矛盾一定程度上是通过让 actor 输出的行为做 temperal scaling,选择一个随机行为,这样的方式来解决的。但如果这还不够的话,就需要 DeepMind 在 2018 年提出的「好奇」机制,提供一种做新行为的内在的奖励。
DeepMind 的这个机制的思路来源就是动物的好奇。因为 TD 学习是脊椎动物才有的,所以很显然,好奇也是脊椎动物才有的。先天对于好奇的奖励机制可以解释为什么人们会沉迷于赌博,因为赌博能够带来足够大的不确定性。同时,也可以解释人们对于社交网络的沉迷,因为社交网络的刷新每次都会出来新的内容,能持续满足好奇。
基础的世界模型
鱼为了能够构建自身经过的区域周边的地图,还需要两个条件:
- 一是要对自己的运动状态有了解
- 二是记住自己和外部世界的关系
能够对自己的运动状态有了解,这是通过前庭感 (vestibular sense) 来达成的。在人类身上,这一感受来自于内耳深处有半规管,其中充满了液体,神经元会监测这些液体的流动来确定运动状态(实际上就是加速度)。而之所以在椅子上转圈久了停下来人仍然会觉得在旋转,就是因为这部分神经元被过度激活了,一直发出信号。
记住外部世界则是通过大脑的内侧皮层 (又名海马体 hippocampus) 实现的,研究发现当鱼游到一个特定空间区域之后,内侧皮层就被激活,这时候视觉、前庭感觉、头向信号被传播到内侧皮层,在那里被混合并转换成空间的地图。
Breakthrough #3: Simulating and the First Mammals
新皮层
之前的动物已经掌握了从实践中学习的能力,甚至脊椎动物已经掌握了 TD 学习的能力。而哺乳动物大脑中新的皮层——就叫新皮层 (neocortex)——将赋予它们以从模拟中学习的能力,或者说是从想象中学习的能力。拥有这种能力之后,小老鼠这样的哺乳动物就可以先想象捕食之后怎么钻进地洞来躲避被猎杀,从而大大提高了生存率。
现在一般认为要进化出这样的能力有两个条件:
- 一是要有广阔的视野,要能够看到周围环境的很多东西,这样才能让模拟更准确
- 而在陆地上,视野远远比水中开阔,所以鱼类选择不模拟,而是快速反应有什么东西正在快速袭来
- 二是可能要有温血性,因为这种模拟计算的计算量会比皮层-基底神经节系统中的强化学习要强得多,而神经元的电信号在低温下效率比较低
- 所以只有哺乳动物和鸟类现在看起来有模拟的能力,这两个是仅有的温血动物
而在人类的大脑中,新皮层的占比达到了 76%,可以说现在人类大脑的主要部分就是新皮层。早期对人类的新皮层的研究发现,新皮层不是服务于单一功能的,所以被分为了视觉皮层、听觉皮层、嗅觉皮层等。而 20 世纪中期神经科学家 Mountcastle 的发现表明:新皮层的不同区块的结构是完全相同的,执行的是完全相同的计算。
这个结论得到了更多实验的支持:
- MIT 的神经科学家切断雪豹的耳朵的输入,然后将视网膜的输入接入到听觉皮层,结果是雪豹的视力非常好
- 另一个实验是人们发现先天性失明患者的视觉皮层并没有变成无用的区域,而是被利用来帮助听觉了
- 这个解释了为什么失明者的听觉、嗅觉经常被认为特别灵敏
Helmholtz 的感知理论和 Helmholtz Machine
新皮层是如何工作的?这还要从 19 世纪德国物理学家 Helmholtz 的理论说起。他的理论是用来解释人类的大脑的很多行为,这些行为包括:
- 可以自动补全不完整的形状
- 一次只能感知到一个属性,比如只能把一张图片看成是鸭子或者是看成是兔子
- 一旦感知到就无法忘记,比如一张模糊的图形里面,如果一下子看出了这是一只青蛙,就一直能看到
Helmholtz 认为,人感知的不是「真正经历的东西」,而是大脑认为存在的东西,这个大脑认为存在的过程就被他称为 Inference 。也就是说,人类并不感知到真实存在的东西,而是感知到从真实存在的东西中推理出来的模拟现实。
1990 年代的时候,Geoffrey Hinton 他们打造了一台机器用以验证 Helmholtz 的思想,他们称之为 Helmholtz Machine。 这个 Machine 由两个部分组成:
- 识别网络 (Recognition Model)
- 负责从数据 \(X\) 去得到一个隐变量 \(z \sim q(z|x)\) ,这里 \(q(z|x)\) 是在输入为 \(x\) 的情况下对 \(z\) 的先验假设,希望将其尽量接近真实后验 \(p(z|x)\)
- 这里 \(q(z|x)\) 就是模型要学习的部分
- 生成网络 (Generative Model)
- 负责用隐变量来尝试生成原始的 \(x\),也就是生成 \(x\) 和 \(z\) 的联合分布 \(p(x,z) = p(z)p(x|z)\)
- 这里 \(p(z)\) 是一个设计好的先验分布,\(p(x|z)\) 是生成模型要学习的部分
其训练过程被称为 Wake-Sleep 算法,过程是这样的:
- Wake 阶段
- 输入真实的数据 \(x\),通过识别网络去得到 \(z \sim q(z|x)\)
- 固定住这个 \(z\),让生成网络尝试使用 \(z\) 去生成 \(x\),通过和原始 \(x\) 比较来调整生成网络的参数(比如最小化 MSE 或者是交叉熵损失)
- Sleep 阶段
- 让生成网络从 \(z \sim p(z)\) 采样,然后生成一个 \(x’ \sim p(x|z)\)
- 让识别网络识别这个 \(x’\),得到 \(q(z|x’)\),然后调整识别网络的参数来让他接近真实后验 \(p(z|x’)\),也就是最小化 KL 散度(让两个分布接近)
用具体的例子来说就是:
- Wake 阶段
- 比如输入一张猫的图像,通过识别网络得到一个隐变量,用生成网络尝试使用隐变量中的信息来重新画出一只猫
- 这里隐变量中的信息可能就是「猫色」、「体形」等等特征
- 因为这里是有原本的猫的图像的,所以可以将画出的猫和原本的猫做对比来优化生成网络
- Sleep 阶段
- 让生成网络从隐变量才分布中采样,然后画出一只猫,再让识别网络去识别这只「假猫」,得到它在隐变量中的分布
- 因为这里是知道真实的采样的隐变量的,所以可以将两者对比,来优化识别网络
其实可以看到这种方式和今天的 VAE, GAN 都有类似之处,Helmholtz Machine 确实就是这些现代模型的启发者。
Helmholtz 认为人类的感知很大程度上 inference 过程——也就是在内心用生成模型对世界进行模拟,然后和感官感知到的证据做对比的过程。现在的这些机器上的生成模型的成功为其观点增加了分量,至少说明类似的原理是行得通的。
因此,一些神经科学家甚至将感知称为是「受限的幻觉」,也就是说大脑不停在生成,而感官的输入是对其生成的一种约束。同时,生成模型的存在可能也能解释为什么我们睡眠的时候会做梦。实际上很多其他动物都会睡眠,主要是为了节约能量,而只有哺乳动物和鸟类有明确的做梦的迹象,因为睡眠的时候就是感官没有在工作的。而从 Helmholtz 结构的角度来说,白天醒着的时候做了太多的识别工作,晚上睡觉的时候多做一些生成工作可以平衡一下。所以如果一直缺乏睡眠的话就会出现幻觉、认知障碍的情况,可能就是要多做一些生成的工作了。
同时研究也发现,想象和识别是不能同时进行的,人在想象的时候明显会出现瞳孔放大的情况,大脑实际上这时候是停止处理视觉的数据的。并且也发现,识别和想象类似的东西的时候,激活的新皮层的神经元区块是类似的。比如看到一只猫和想象一只猫实际上激活了类似的新皮层神经元。
所以可以认为新皮层是这么工作的:渲染出环境的模型,然后不停进行预测。所以一旦有任何和预测不一致的地方,就会引起惊讶。所以比如在走路的时候,如果都是平路,那么就是和预测的结果一致的,不会引起注意,但是一旦有一个坑让脚发现没有踩在地面上,就是和模拟不一致,从而引起惊讶。
实际上从双侧动物开始,就一直在尝试进行预测:
- 双侧动物(的反射回路):预测反射激活,也就是用一个神经元的激活来预测另一个神经元
- 脊椎动物(的基底神经节):预测未来奖励,比如猴子通过几何图片来预测糖水的奖励
- 哺乳动物(的新皮层):预测一切
新皮层赋予的能力
新皮层的生成功能赋予了哺乳动物以很多新的能力:
第一是替代性试错。哺乳动物可以想象如果选择了一种做法会造成怎么样的后果,研究表明老鼠走迷宫的时候遇到决策困难的地方会停下来进行想象,如果走两边的路径会怎么样。
第二是反事实学习。强化学习的一个问题是有些时候其实情况并不算好,但是仍然有收获,那仍然有 reward 来进行强化,比如鱼去捕猎其他小鱼,只捕猎到一条,其实很少,但是因为吃到了食物,所以仍然对刚刚的行为进行了强化。在机器学习的强化学习中,这里实际上是会做一个 normalization,因为好坏是相对的。而对于哺乳动物来说,可以想象如果不是采用这个策略,那么能捕猎到多少条鱼,是不是会比现在更多,从而对行为进行反思,比如和猴子玩石头剪刀布,猴子如果输了,下一次会倾向于出上一次可以赢的选项。
反事实学习实际上是一种解决信用分配问题的更高明的方法,对比一下:
- 双侧动物:通过阻断、潜在抑制、遮蔽等方法进行的基本的信用分配
- 脊椎动物:通过 Critic 预测未来奖励变化的时间分配信用
- 哺乳动物:基于反事实想象来分配信用(是什么真正导致了事件的发生?)
第三是情节记忆的能力。研究发现我们其实并不是完全记住了一个过去的场景,而是在模拟这个场景,情景记忆在回忆的过程中被填充(就像填充视觉的几何图形一样)。这就是为什么情景记忆非常真实,但其实不是很可靠。这里对于过去的模拟其实是和想象未来的时候对未来的模拟类似的。所以这里的核心看起来其实是新皮层,但是其实海马体也起到了很重要的作用。我们知道之前脊椎动物已经有了海马体(内侧皮层),达成了一些简单的记忆,比如鱼可以在海马体的帮助下记住周边的空间。但是海马体做的其实是快速的场景记忆,当新的信息进入大脑之后,海马体迅速将其编码成一个事件的 pattern,之后这个 pattern 会被转移到新皮层中。
所以整个记忆流程大概是这样的:
- 感官输入,然后感觉新皮层进行初步的处理,形成临时的对世界的模拟
- 海马体迅速捕捉到感觉新皮层传来的 pattern,将其编码成一个初步记忆代码
- 到这里形成的记忆是粗略的,是一种简单的模式识别,但是速度非常快,因为慢了以后事件就消失了
- 接下来的几小时到几天内,海马体会反复 replay 这些 pattern,尤其是在睡眠和休息时
- 通过这样的 replay,海马体内部的突触会强化,形成相对稳定的中期记忆
- 再往后的时间里,海马体会反复将编码后的 pattern 传回新皮层,建立更加稳定的长期记忆
然后当要对长期的记忆进行回忆的时候,就是在新皮层中进行模拟。所以海马体损伤的人会无法形成新的记忆,但是并不影响已经存在的遥远的记忆,这就是著名的患者 Molaison 的情况。
基于模型的强化学习
直接在复杂的棋类游戏中使用强化学习的效果是不够好的,所以 AlphaZero 这样的模型实际上用到了另一个技巧,就是会搜索策略。在对手落子之后,对可能的不同的走法进行上千次模拟,然后选择其中获胜比例最高的走法。这个实际上相当于是不直接选择单个 Actor 的 action,而是有一组 actor 共同行动,然后从中挑出最好的那一个,这是一种对于 TD 学习的简单扩展。我们一般把这种方式的强化学习叫作基于模型的强化学习 (Model-Based Reinforcement Learning,MBRL)。
而在自然界要做类似的事情比围棋要难得多,因为这里的搜索策略是固定的(选择哪些 action 来进行模拟),而自然界每一种不同的场景都需要一个不同的搜索策略。人脑在不同的场景下会非常灵活使用不同的策略,有时候会不假思索,有时候会进行非常丰富的想象模拟,这远超现在 AI 的能力,那么人是如何做到的呢?
新皮层是模拟的地方,而研究表明前额叶皮层 (主要是其中的 aPFC) 是控制模拟的地方。如果老鼠的 aPFC 损伤,那么就会变得非常冲动,失去计划的能力。而 aPFC 是通过「预测自我」的方式来对模拟进行控制的。新皮层形成的是一个世界模型,它时刻在进行对世界的模拟,预测外部的物体接下来会做什么;而同时 aPFC 形成的是一个自我模型,从海马体、下丘脑等地方获得输入,预测「我」本身接下来会做什么。而当 aPFC 的预测结果和实际发生的情况不一致的时候,就也产生了一个(对于 aPFC 的)惊讶,然后就会触发模拟。因为预测不一致就代表了一种不确定性。而这里 aPFC 因为是在预测的,所以本身就有几个可能的结果,这几个结果就可以作为接下来要模拟什么的内容。
目标、习惯、工作记忆、自我控制
一个研究先让老鼠去抬杆然后给奖励食物,老鼠就学习到了抬杆。然后之后给老鼠一些污染了的奖励食物(直接给),发现大部分老鼠就变得没有那么积极去抬杠了。这可以说明老鼠这里不是简单的无模型强化学习,而是在动作之前会模拟一遍奖励,发现奖励没有那么吸引人了就不做动作了。但是发现那些之前抬了非常非常多次杆的老鼠会继续抬杆,这就是我们一般说的「形成了习惯」。这里的原理就是基底神经节已经接管了这个动作,在做的时候不再进行反思模拟了。也就是说习惯是一种由刺激直接触发的自动化的行为,是无模型强化学习的情况。习惯的存在帮助我们在做很多事情的时候可以轻松完成,但是如果习惯在错误的场景就会对我们不利。
基底神经节这样的无模型强化学习系统是谈不上有一个「目标」的,因为它的功能就是做动作然后获得最大的奖励。但是 aPFC (agranular prefrontal cortex,无颗粒前额皮层) 确实是有一个目标的,因为它是要为了达成一个特定的目标然后去进行规划的。比如去超市购物,前者会直接往之前强化过的效率最高的路径走,而后者会构建一个超市的大致的布局,模拟各种可能的路径,然后进行选择,这里就必须要有一个明确的目标比如是为了更快完成购物。当然某种程度上来说无模型系统在学习过程中也是有一个目标的,也就是其奖励规则。但这实际上只是一种奖励的依据,可能并不是特别具体的,所以比如我们问为什么 AI 做了这个动作,无模型系统只能回答「因为历史上这个动作获得了更多奖励」,而有模型的就能回答是「为了达到这个目的」。
这里可以对比一下 aPFC 和感知皮层的区别。在感知皮层中,有一个 Layer 4,是用来连接感官的输入,开始进行模拟的。而 aPFC 在发育过程中会有 Layer 4,也就是说会通过外界的输入来建立内部模型,但是发育成熟之后 Layer 4 就会萎缩,它的 input 不再有原始的感官数据,而是仅有其他新皮层和基底神经节的信息,通过整合这些更抽象的信息来生成更高层的意图和目标。
同时 aPFC 在进行控制的时候还需要「工作记忆」,也就是在执行一个意图的时候要保持这个意图所需要的记忆。aPFC 的做法其实就是持续唤起新皮层对要保存的场景的模拟,从而在一段时间内记住这些场景。以啮齿动物为例,当它在树林中寻找坚果时,需要记住哪些树木已经采过,从而避免重复采摘,啮齿动物的 aPFC 就会重复模拟之前采过的树木。与海马体做对比的话,海马体是能迅速编码一些信息,但是这些信息是为了能够长期存储的,之后也会慢慢整合到新皮层中。而工作记忆就完全是临时性的,时间稍久就忘记了,以计算机来类比的话,其实非常像 register。通常来说,工作记忆保存的是需要临时操作、实时更新的信息。例如,解决数学题时暂存的数字、语言理解过程中临时保留的句子结构等。海马体则主要对环境信息、情境细节、事件的背景等进行快速编码。
另外,aPFC 还有一个功能就是抑制杏仁核 (amygdala)。杏仁核的作用是触发一些本能的情绪反应(恐惧、欲望、攻击性等等),aPFC 抑制之下就会人类行为就会相对更加理性和脱离本能反应。而 aPFC 的工作是非常耗能的,所以人在疲惫、压力大的时候 aPFC 的能力就会减弱,所以就会变得更加动物性,即更加冲动、易怒等等。
Breakthrough #4: Mentalizing and the First Primates
灵长类的群体
研究发现对于灵长类动物来说,大脑的大小和它们生活的群体的大小呈正相关。而这种相关性在其他动物上是没有的。对于各种动物来说,群居是有收益也有损失的。收益主要是更加安全,比如一群斑马狮子来说也是有威胁的,而一只斑马就完全是猎物了;但是问题就是一个群体中会出现内部的对于配偶、食物的争斗,这种争斗是要消耗宝贵的能量的。所以一般这些群居动物都会进化出一种信号和服从机制,比如鹿会进行锁角而不是真的你死我活的争斗来决出领导者,败者就要对胜者进行服从。建立了这样的服从和等级的结构之后群体就会更加稳定高效。灵长类至此和其他的群居动物没有太多差异,但是一个区别是灵长类具有一个比较特别的能力,即拥有心智理论 (theory of mind),能够推断他人的意图和知识。
研究发现灵长类群体中的社会等级非常重要,灵长类动物都对社会等级的存在和变化极为敏感。比如先播放上层成员发出 dominance 的声音,然后下层成员发出 submission 的声音,狒狒群体不会有什么反应;而如果反过来播放下层成员发出 dominance 的声音,然后上层成员发出 submission 的声音,狒狒群体就会非常惊恐,盯着扬声器想看看到底发生了什么。而灵长类群体中的社会等级并不是和其他很多哺乳动物一样是看谁的力量强的,很大程度上取决于「出身」,和人类一样。比如对于所有的雌性来说,地位最高的是地位最高的家庭的年长者,然后是她的女儿,接下来才是地位稍次的家庭的年长者,她的女儿,以此类推。而家庭地位的更迭要看整个家庭的力量,如果上位家庭的力量看起来要弱了,下位家庭就可能发起反叛挑战。在这个挑战中,他们都可能是会招募家族(群体)之外的成员来进行帮忙的。
灵长类形成这样子的情况可能和他们曾经在二叠纪-三叠纪灭绝事件后处于一个特殊的生态位有关系。在这个时期,这些灵长类主要是居住在树顶采摘果子来获得能量,这使得整个生活非常容易,获取食物所要付出的能量很少,同时有大量的空闲时间。所以对这些灵长类来说,与其进化出强大的力量,不如进化出更大的大脑来进行社交。 所以在这个时期,演化的压力变成了社交的军备竞赛,一场政治智慧的争夺战。其结果就是今天很多人类的社会本能的蓬勃发展,其中包括看起来比较正面的:友谊、互惠、和解、信任、分享,也包括比较负面的:裙带政治、欺骗等。支撑这些新动作,这些政治行为的能力就是进行心智理论的能力。
建模他人心智、逆强化学习
最早的哺乳动物的的大脑只有不到 0.5g,而最早的猿类的大脑已经来到了 350g。一个问题就是,这里到底增加了什么?其中有很多部分确实只是已有区块的等比放大,但是也确实有新的部分,其中之一就是 gPFC (granular prefrontal cortex),它环绕着 aPFC。之所以说这部分是新的,并不是因为其微电路,其微电路仍然是和其他新皮层区域一样的(所以应该说 gPFC 也是新皮层),而是它的 IO 的连接性。
gPFC 以 aPFC 的状态作为输入,所以它构建了一个关于自己的内在的模型,其作用可以说是「解释意图」。 回顾一下,新皮层形成了一个世界模型,对世界进行时时刻刻的模拟;而 aPFC 形成了一个对新皮层的模拟,通过预测自我的行为来形成一个更上层的意图,来更好地进行控制;而 gPFC 则是更进一步,对 aPFC 进行预测,也就是来预测 aPFC 形成的意图是什么,这就起到了解释意图的效果。
举一个例子,如果我们把灵长类动物放到一个迷宫里面,当他左转的时候我们问「为什么左转」,在不同的抽象层次上会有不同的答案:
- 从反射的层次来说,左转是硬编码的规则,也就是朝着气味的来源的方向(左侧)移动
- 从脊椎动物的 TD 学习的角度来说,左转是可以让未来的奖励最大化的行为
- 从哺乳动物的新皮层和 aPFC 的角度来说,左转是因为知道左边有食物,这是一个整体的意图,就是去左边取食物
- 从灵长类的 gPFC 的角度来说,左转是因为我知道我现在很饿,而饿的时候吃食物很爽,同时我知道左边有食物
- 这种对思考这件事情本身能够思考的能力被心理学家和哲学家称为 metacognition
而建模他人心智的就是将「认识自己」的方式运用到「认识他人」上,即会将自己投射到他人的处境上来理解他人,从而获得心智理论。
心智理论也赋予了灵长类以「观察他人的动作来学习新技能」的能力。很多非灵长类的动物也可以通过观察别人怎么做来学习,但是都只是一种「对于选择的学习」,也就是说本来不知道在这种场景下应该选择使用自己已有技能的哪一种,现在知道了。这个使用简单的反射就可以实现,比如乌龟可以有一个反射是去看其他乌龟正在看的方向。而灵长类所能通过观察学到的东西可以是完全新的技能,之前从来没做过的事情。
这件事情的延伸意义就是对于工具的使用。一旦有一只灵长类动物发明了使用一种工具,那么就可以被其他的目击者学会,然后代代相传下去。
2010 年的时候,Andrew Ng 等人通过「逆强化学习」 IRL 的方法做出了能够自动驾驶遥控直升机的 AI。这里的做法就是给 AI 以人类开车的视频,然后训练 AI 推断人类开车过程中行为的意图,然后自己推断出 reward function 应该是什么样的。然后最后再使用常规的 RL 的方法去进行学习。这里 IRL 做的事情在原理上就很像 gPFC 做的事情。
Breakthrough #5: Speaking and the First Humans
人类语言与动物之间交流的区别
对于人类独特性的论述古已有之,但是现在实际上证明人类的大脑和黑猩猩的大脑并没有结构上的区别,只是更加放大了一些而已。而使得今天的人类与猩猩如此不同的主要原因可能还是沟通方式的区别,也就是语言。
动物之间当然也是有交流的,但是这种交流的方式是硬编码在基因中的。完全处于不同环境下抚养的其他灵长动物,见面之后仍然能用一些叫声和手势进行沟通。同时我们知道我们可以用一些语言来训练猫、狗等,来和他们进行沟通,但是这实际上只是一种基本的 TD 学习:即我们在训练狗的过程中会给它一些奖励,狗通过 TD 学习知道听到这些声音之后做某些动作就能获得未来的奖励。
所以语言学习区分了两种标签:命令标签和陈述标签,训练猫狗的语言只能是前者,也就是产生一个命令让它们做事情,而只有人类语言可以表达陈述性的标签。
另外,还有实验尝试从黑猩猩的幼年开始教人类语言,最后达成的结果是可以达到两三岁幼年人类的语言水平,可以使用简单的词汇的组合。能学会一定的人类语言这个是合理的,因为大脑的结构上确实没有什么区别。而之所以只能达到两三岁人类的水平,可能和缺乏学习本能有关(下文会提到)。
语言的能力、奇点
语言的最大意义在于可以在不同个体之间传递大脑的内在模拟,从而做到「从他人的想象中学习」。这里对比一下之前的学习方式:
- 双侧对称动物的强化学习、脊椎动物的 TD 学习:从实际行动中学习
- 拥有了新皮层的哺乳动物的学习:从想象(模拟)中学习
- 心理化了的灵长类动物的学习:从观察他人的行动中学习
- 拥有语言的人类:从他人的想象中学习
语言还赋予了人类以拥有共同的想象从而形成凝聚力的能力,也就是赫拉利说的「想象的共同体」。
更重要的是其机制。类似于:DNA 的强大之处不在于其产生造物(具体的心脏、肢体等器官),而在于其运作的机制,自然选择压力可能最终挑选出最好的组合;语言的出现让人类在几代几十代之后将最有利于生存的知识挑选保留下来。黑猩猩缺乏语言,所以好的内在模拟无法被传播和保留,因此超出了一定的复杂性 threshold 的发明是永远无法达到的。
而当知识的积累到了一定的量,就达到了一个奇点。人类为了应对更多的知识量,发生了几个变化:
- 进化出了更大的大脑,从而让单个个体能够承载更多的知识
- 让知识分布在不同的个体中,比如一些人是矛的制造者,一些人是衣服的制造者,也就是产生了专业化
- 发明了书写,可以让知识的保存不局限于大脑中
大脑中的语言、课程
今天我们已经知道,对于人类来说,运用语言主要是两个脑区负责的:
- Broca’s Area:负责语言的产生,如果损伤的话人仍然能理解语言,但是无法产生流畅的语言,说的话语法非常混乱,只能表达简单的意义
- Wernicke’s Area:负责语言的理解,如果损伤的话人无法理解语言,可以流畅说话但是产生的语言没有意义(胡言乱语)
同时我们知道这两个区域负责的是「语言本身」,而不是某种特定的语言形式。也就是说这两个区的损伤带来的这些症状是会体现在说话、书写、手语等各种语言形式上的。
而这两区实际上也是新皮层,只是我们将这两个位置命名成了如此,其结构和黑猩猩的这个位置并没有什么区别。所以也可以说,黑猩猩实际上也是有这两个区的,那么为什么黑猩猩就无法产生语言呢?
实际上我们现在已经知道,我们的情感表达才是黑猩猩手语与吼叫的直系演化,我们的语言其实是完全不同的东西。人类现在控制面部实际上就有两套系统,一个是通过情感直接控制的,这是一些古老的反射;另一套是新皮层控制的,提供对面部的自愿控制。一个病例就是发现自己无法主动控制面部肌肉了,但是在开心的时候还是可以笑。同时,那些 Broca’s Area 或者是 Wernicke’s Area 受损的人也同样可以正常哭和笑。所以也就是说,我们完整继承了黑猩猩的手语、吼叫能力,作为情绪表达。而语言的能力则是完全重新学习来的。
语言相对于其他的技能可以说是非常复杂的,所以其实并没有能够印刻在基因中。而基因对语言的安排是:强制了一套完整的学习课程,经过了这个课程之后人类就会学习到语言。其实类似的事情在其他动物上也有,比如鸟类不是生来就会飞行的,但是他们会根据基因自然地去扑腾翅膀等,这样就能慢慢学会飞行。而人类的婴儿,在四个月大的时候就会去尝试进行交流,然后九个月的时候会有「共同注意」的机制,希望成人能够解释一个东西是什么,从而让自己为这个东西贴上标签。同时人们发现,Broca’s Area 和 Wernicke’s Area 这两区并不特殊,如果在婴儿的时候切除掉这两区,那么人仍然能学会语言,只是占用了其他的新皮层作为这两区的功能。
所以黑猩猩无法真正学会语言的原因可能就是在这里:他们在基因上没有编码这样的「课程」,从而无法持续学习语言。
语言的出现还有一个比较难解释的问题,就是语言早期的功能是利他的,而不是利己的。我们其他的那些进化出来的项目,无一例外都对个体自身的生存有着很大的帮助,但是语言的作用可能是教授他人。所以这里的区别就是语言的进化是一种「群体选择」,而不是「个体选择」,拥有语言的群体的生存状况会更好。
实际上动物在语言之前也有一些利他行为,主要是两种:
- 一是亲属选择,即会在涉及直系亲属的时候有 bias,这个在基因角度来说是很合理的
- 二是互惠利他,即期望对方会有回报的时候进行的利他行为
人类最早使用语言也许是在亲子之间,主要是为了让后代学会工具的使用。而之后语言的使用就会扩展到非亲属中,整个群体中。在这个时期,人们首先会用语言来谈论「八卦」,即分享他人的道德违规行为、讨论关系变化。所以这种情况下,cheaters 会有更高的作案成本,会更容易被惩罚;反过来说,也有利于让帮助他人的人得到更多的奖励。所以语言有助于形成一个互惠利他系统,长此以往就会让进化出更高水平的利他主义成为可能。于是这里就形成了反馈循环:利他主义程度高了以后,每个人向他人分享信息的程度就更高。然后更高的分享信息的程度又会促进语言技能的增加,然后使得八卦有效性更高,进一步促进利他主义的发展。人类给他人贴上善恶标签的本能可能也来自于此。
完美风暴:人类是如何出现的
人类和黑猩猩的分歧大概发生在七百万年前。而直到两百多万年前,大脑的容量都是保持不变的,但是之后却在很短时间里面迅速变大了三倍。
一千万年前,东非是一片绿洲,树木繁茂,我们的祖先就住在树上。但是随后地壳板块的移动让这里形成了新的山脉和,沿着今天的埃塞俄比亚延伸,这个地区就是今天我们所说的「东非大裂谷」。新的山脉将大裂谷两侧的黑猩猩分开来,在西侧,环境和之前类似,黑猩猩们基本保持了祖先的状态;而在东侧,树木逐渐减少,形成了越来越开阔的草原,于是演化压力开始发挥作用,这批「东侧猿」后来就变成了人类。到距今大概四百万年前,这些东侧猿的样子仍然和西侧的黑猩猩差不多,唯一区别是他们开始直立行走。不管说直立行走是为了什么,但是这并不需要额外的脑力,大脑的容量在这个时期也是基本保持不变的。
到了两百多万年前,这时候新的草原上已经生活了大量大型哺乳动物,象、斑马、长颈鹿、野猪、豹子、狮子、鬣狗等等,而我们的祖先是这里面顶级猎食者。他们之所以能做到是因为发明了工具:一个是 Oldowan tools,可能是一种打击制成的黑曜石或者石英的薄片(Oldowan 这个词就是旧石器时代的意思),还有石斧等。这些人被称为 Homo erectus 直立人。值得注意的是这里这个名字是比较糟糕的,因为在称为 Homo erectus 之前这些人就已经直立行走了。Homo erectus 的捕食方式可能是长时间追逐猎物,通过耐力上的优势来追上对方。他们也因此进化出了更多强化耐力的特征:腿部变长、脚弓拱起、无毛、汗腺增多等等。另外,烹饪也应该是在这个时期被发明,烹饪可以帮助直立人从同样的食物中获取更多营养,提供更多的热量盈余。
而随着这段时间大脑的增大,也出现了一个新的问题,就是它无法通过产道。直立人的应对进化是早产,将没有发育完全的幼崽直接生育出来,真正大脑长成需要再过 12 年。这是为什么其他很多动物的幼崽剩下来就会站立甚至奔跑,而人类婴儿要差得多的原因。
LLM 与人的对比
新皮层通过渲染内部模拟的方式来推理,这个机制让人类经常在一些问题上犯错。比如考虑这个问题:一个人喜欢独处,喜欢柔和的音乐,戴着眼镜,那么他更有可能是一个图书管理员还是一个建筑工人?一般的回答都会是前者,因为更符合我们想象出来的图书管理员的形象。但是实际情况是,后者的人数是前者的几十倍,所以从统计上来说其实更有可能是后者。我们之所以认为是前者是因为我们能轻易渲染出前者的形象,而想象后者则困难得多。也就是说我们在做这种推理的时候只是去填补角色和场景,而忽略因果和统计关系,这也是人类的很多 Bias 的来源。一定程度上说这个有点像 LLM 工作的方式,就是填补空缺。
当然,纯从语言的层面来说,LLM 只会预测下一个单词,而人类在预测下一个单词的时候是会有一个新皮层内的世界模型进行模拟的。相比之下 LLM 这个还是肤浅得多。这里有一个问题就是「回形针问题」,即人类在提出要求说工厂要尽可能生产更多回形针,这个要求实际上是有很多的隐含意思的,比如并不是要把整个地球都变成生产回形针的工厂;比如目的其实是多赚钱而不是真的就想要回形针。也就是说这样的要求背后有一些微秒的约束,要理解这样的约束最重要的能力就是要对提问者的心智建模,也就是心理化过程中带来的智能。